RNA Secondary Structure Prediction using a Transformer Encoder
Published: 25 MAY 2026
(2026-01-01 — 2026-03-30)
A Transformer-based system for RNA secondary structure prediction that translates nucleotide sequences into dot-bracket representations, evaluates structural validity with sequence-aware metrics, and analyzes how preprocessing, model design, and postprocessing affect prediction quality.
RNA Secondary Structure Prediction using Transformers
This project explores RNA secondary structure prediction as a structured sequence labeling problem. The goal is to translate an RNA nucleotide sequence into its corresponding dot-bracket representation, where paired bases are represented by matching brackets and unpaired bases by dots. Because RNA structure depends on long-range interactions between distant nucleotides, the task is not only about local classification, but also about producing globally consistent structural outputs.
Project Goal
The main objective of the project was to build and analyze a complete end-to-end prediction pipeline for RNA secondary structure prediction with a Transformer encoder. Instead of focusing purely on hyperparameter optimization, the project aimed to answer a broader question: Can a Transformer-based model learn meaningful sequence-to-structure mappings under realistic computational constraints, and how far can structural quality be improved through evaluation and postprocessing?
Dataset and Preprocessing
The dataset was derived from bpRNA-based structure sources and required extensive preprocessing before it could be used for training. Raw sequence-structure pairs were collected from two different archives, normalized into a shared dot-bracket format, checked for malformed entries, and deduplicated.
A particularly important part of the preprocessing pipeline was the handling of ambiguous nucleotide symbols. To study this systematically, three dataset variants were created:
base_mode=0: strictGUAC, using only the four standard RNA nucleotidesbase_mode=1:GUACN, mapping ambiguous IUPAC symbols toNbase_mode=2:GUAC+, keeping ambiguous IUPAC symbols explicitly
In addition, sequences longer than a chosen maximum length were removed rather than truncated, ensuring that all retained samples represented complete biological sequences and structures.
Model Architecture
The core model is a Transformer encoder tagger. Each nucleotide sequence is encoded into token IDs, embedded into a continuous representation space, and enriched with sinusoidal positional encodings. The encoded sequence is then processed by multiple Transformer encoder blocks with:
- multi-head self-attention
- residual connections
- layer normalization
- feed-forward layers
- dropout
The output layer predicts one structural token per sequence position. Since the model predicts tokens independently at decoding time, structurally invalid outputs can still occur even when token-level accuracy is high.
Why This Problem Is Interesting
RNA secondary structure prediction is a strong test case for sequence models because it combines local token prediction with global structural constraints. A model may classify many individual positions correctly while still producing an invalid structure overall. This makes the task especially interesting from a machine learning perspective, because standard token-level loss functions do not directly enforce structural consistency.
“High token accuracy does not automatically imply a valid RNA structure.”
For that reason, this project explicitly goes beyond standard token classification and includes structure-aware evaluation and repair methods.
Evaluation Strategy
The project evaluates model quality using both local and global metrics. Instead of relying only on accuracy, the evaluation framework measures several complementary aspects of prediction quality:
- validation loss
- token accuracy
- sequence exact match
- paired-position F1
- invalid rate
This combination makes it possible to distinguish between models that predict plausible local patterns and models that actually recover valid or near-valid RNA structures.
Postprocessing of Predicted Structures
A major part of the project was the comparison of two postprocessing strategies for repairing invalid dot-bracket predictions.
Kill-to-Dot (KTD)
KTD is a simple validity repair method. It removes unmatched closing brackets immediately and replaces leftover unmatched opening brackets at the end with dots. This guarantees a valid output, but it may also destroy useful structural information.
Dynamic-Programming-Guided Salvage (DPGS)
DPGS is a more advanced postprocessing approach that uses model confidence scores to preserve plausible bracket assignments whenever possible. It applies a dynamic-programming-based repair procedure separately for each bracket type and constructs the highest-scoring valid balanced sequence under the model logits.
Compared with simple deletion-based repair, DPGS is more selective and often produces better sequence-level results while maintaining structural validity.
Main Findings
The experiments showed that Transformer encoders are able to learn meaningful RNA sequence-to-structure mappings. Across model variants, the system achieved strong token-level performance, but the results also made clear that token-level optimization alone is not sufficient for this task.
Several important patterns emerged:
- deeper models consistently improved token-level and sequence-level performance
- moderate regularization performed better than very weak or very strong weight decay
- the best preprocessing strategy depended on model capacity
- postprocessing had a major effect on structural validity
- structure-aware evaluation revealed differences that pure token accuracy would have hidden
The best model achieved strong validation performance even without postprocessing, and structural repair methods further improved sequence-level correctness.
Structure-Level Analysis
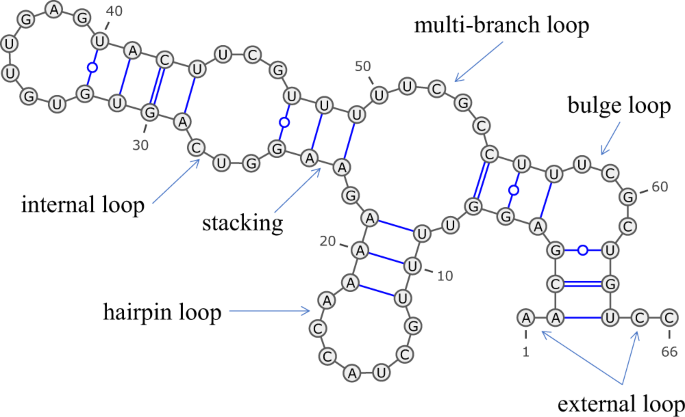
Beyond dot-bracket prediction itself, the project also included a downstream analysis step that assigns higher-level structural labels to predicted RNA elements. A deterministic labeling algorithm was used to classify positions into categories such as:
Sfor stemHfor hairpinBfor bulgeIfor internal loopMfor multiloopEfor exterior regionXfor exterior mixed region
This made it possible to analyze predictions not only as bracket strings, but also in terms of biologically meaningful structural components.
An additional validation study of this labeling procedure revealed that the underlying dataset itself does not follow one fully uniform annotation convention. This was an important finding because it showed that some apparent mismatches were caused by inconsistencies in the source annotations rather than by errors in the implementation.
Technical Scope
The project includes a full workflow around the model, not just the training script. The repository supports:
- dataset construction and normalization
- filtered dataset generation for different nucleotide handling modes
- conversion into tagging format
- training from scratch
- resuming from checkpoints and snapshots
- single-sequence inference
- metric plotting
- checkpoint inspection
- comparison of multiple model runs
- comparison of postprocessing methods
This made the project not only a modeling experiment, but also a structured research and tooling pipeline for systematic experimentation.
What I Learned
This project deepened my understanding of how Transformers behave on structured biological sequence tasks, especially when local classification objectives interact with global validity constraints. It also showed the importance of careful preprocessing, meaningful evaluation design, and postprocessing strategies when building real-world machine learning systems.
From a practical perspective, the project combined:
- model design
- data engineering
- experiment management
- metric analysis
- structural postprocessing
- scientific interpretation of results
Conclusion
Overall, this project demonstrates that Transformer encoders are a strong and practical baseline for RNA secondary structure prediction. At the same time, it highlights an important limitation of standard token-level training: accurate local predictions are not enough when the output must satisfy global structural rules. By combining a Transformer model with structure-aware evaluation and postprocessing, the project builds a complete and effective pipeline for predicting and analyzing RNA secondary structure.